So, you probably remember this from the most recent episode of The Mentalist / Bones / Castle / Criminal Minds / Numb3rs:
SEXY YET PROFESSIONAL DETECTIVE: What have we got?
SASSY JUNIOR DETECTIVE: Nothing. All of our leads have dried up like Cher’s ovaries.
GRUFF SENIOR LAW ENFORCEMENT OFFICIAL: We’ve got to wrap this thing up. I’ve got the mayor breathing down my neck.
MAYOR: Hhhhhhhhhh. Hhhhhhhhhh.
G.S.L.E.O.: And now he’s drooling.
S.Y.P.D.: We’ll keep after it, but we’re a bit short-handed after half of the department was beheaded and, ironically, eaten by The Vegan Killer.
G.S.L.E.O.: I don’t want excuses. I want someone behind bars.
S.J.D.: You and my alcoholic ex wife.
SOCIALLY INAPPROPRIATE GENIUS: Actually, we know that the comptroller picked up his dry-cleaning on Wednesday. The same Wednesday that the chimney sweep showed up at the wedding in a curiously un-besooted pair of dungarees. Thus, the heiress was murdered by the delivery man who brought the Martinizing agents to the dry cleaners, also on Wednesday. Also, he was her half brother.
And, scene.
Thanks to research just published in PNAS by a group out of Cornell, we are now one step closer to living in a dystopian panopticon in which our associations can be inferred by any monkey with a laptop. Soon, Patrick Jane will be back to doing parlor tricks, Richard Castle will be back to making a living as an imaginary writer, and everyone else will be in prison for consorting with each other.
More specifically, the authors investigate whether they can infer a social connection between two people on the basis of their having been at the same place at the same time on multiple occasions, using data from Flickr. They look at 38 million pictures that contain both a timestamp and a geo-tag, indicating the time, latitude, and longitude at which the picture was taken. They define a co-occurrence of two Flickr users as having pictures taken within a time t of each other and within the same geographic region: a square(ish) region of length s latitude or longitude degrees on each side. The social dimension of the data comes from Flickr’s networking functions, which allow users to specify their links to others.
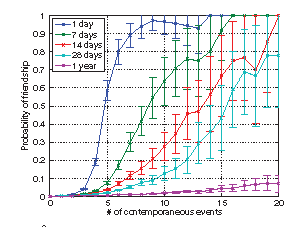
They find that the greater the number of co-occurrences for a pair of users, the more likely it is that they are friends. This is not particularly surprising, although the magnitude of the effects are quite striking. For example, here is one graph from the paper:
 |
| Part of Figure 2D from the paper. In this case, the spatial range for co-occurrence is defined by s = 1.0 degrees (about 55 miles by 65 miles where I live). The different curves correspond to different time windows. |
The probability that two randomly selected Flickr users are friends is less than 1 in 7000 [Corrected. Original post said 1 in 700]. However, if two users have uploaded pictures from the same 1 degree by 1 degree region within a day of each other on five different occasions, there is nearly a 60% chance that they are friends. If they have done it more than eight times, the chance is more than 90%.
In other words, if you and your accomplice both upload photos from the same dry cleaner every Wednesday, even a non-genius will be able to figure out that you know each other. This is how Strangers on a Train will end in the 2032 remake starring Freddie Highmore and Abigail Breslin.
For those interested in looking at more pretty graphs, the article is Open Access, and can be found
here.
For those interested in mounting a futile defense against the Orwellian State, more information about geo-tagging and privacy can be found here, including ways in which you may inadvertently be sharing location information without meaning to.
Crandall, D., Backstrom, L., Cosley, D., Suri, S., Huttenlocher, D., & Kleinberg, J. (2010). Inferring social ties from geographic coincidences Proceedings of the National Academy of Sciences DOI: 10.1073/pnas.1006155107